
티스토리 뷰
1. 물리적 데이터 모델링 소개
| 논리적 데이터 모델링 | 물리적 데이터 모델링 |
| 특정 DBMS 제품을 고려하지 않고 관계형 데이터베이스 이론에 맞게 설계 |
특정한 DBMS 제품의 특성에 맞는 최적화된 데이터베이스 설계 |
논리적 데이터 모델링 단계는
위의 설명처럼 특정한 DBMS 제품을 고려하지 않고 관계형 데이터베이스 이론에 맞게 설계하는 단계라고 한다면
물리적 데이터 모델링 단계는
우선 논리적 데이터 모델링 단계에서 얻어진 정규화된 관계 스키마를 실제 데이터베이스의 특성에 맞게 효율적으로
구현하기 위한 작업과 개발하려는 DBMS의 특성에 맞게 실제 데이터베이스 내의 개체들을 정의하는 단계를 포함한다.
물리적 모델링 단계에서 가장 중요하게 고려해야 하는 사항은 바로 시스템의 응답시간과 데이터의 처리량이다.
당연히 시스템의 응답시간을 최소화해야 하고, 데이터 처리량을 최대화하기 위한 설계를 해야만 하며, 이를 위해서
이전에 정리했던 여러 요소들을 고려해야만 한다.
시스템의 응답시간을 줄이고 데이터의 처리량을 최대화하기 위해서는 먼저 전제되어야 할것이 바로
데이터 사용량 분석과 사용자들의 업무 프로세스 분석이다.
설계자들은 이를 통해 데이터 사용량이 집중이 되는 테이블들에 대해서 보다 효율적으로 사용자들의 프로세스가
동작할 수 있도록 하기 위해 역정규화를 수행하고, 인덱스를 포함한 데이터베이스 내의 개체들을 정의하는 작업들을
수행하게 된다.
역정규화(De Normalization)란?
논리적 데이터 모델링 단계에서 수행했던 정규화 과정을 거치게 되면, 테이블들은 가장 작은 논리적인 단위로
나누어지게 되는데, 이런 상태로 데이터베이스가 구현되면 궁극적으로 원하는 정보를 얻기 위해서 많은 테이블을
조인 해야 하는 등 여러가지 성능상의 문제가 발생하게 된다.
그러므로 성능 향상을 위해서 정규화에 위배되는 행위를 일부러 하는것을 말하는것으로 물리적 데이터 모델링 단계에서
가장 중요한 단계라고 할수 있다.
역정규화 작업이 끝나게 되면,
실제 데이터베이스로 구현될 형태의 테이블과 테이블의 관계가 정의되는 것이며, 이후에 인덱스나 저장 프로시저, 함수,
트리거 등등 이전 장에서 정의했던 데이터베이스 내의 개체들을 정의하고 물리적인 데이터베이스를 생성하면 데이터
모델링 작업은 끝나게 되는 것이다.
2. 역정규화(De Normalization)의 유형
역정규화란 시스템의 성능 향상을 위해서 정규화에 위배되는 행위를 일부러 하는것을 말한다.
즉, 성능 향상을 위해서 정규화를 무시하는 것이다.
아마도 이 역정규화 때문에 많은 분들이 데이터 모델링을 어렵고 모호하게 생각할 수도 있을 것이다.
왜냐하면 역정규화는 정답이 없기 때문이다.(데이터 사용량 분석과 사용자들의 업무 프로세스에 따라 달라지기 때문)
①컬럼 역정규화

위와 같은 [동아리 테이블]이 있다고 하자.
그런데 [동아리 등록 테이블]에 조회를 할 경우에는 [학생 테이블]과 조인해서 학생 이름을 기본적으로 가지고 와야 하며,
[동아리 테이블]과 조인해서 동아리명을 가지고 와야 한다.
그러므로 [동아리 등록 테이블]을 조회할 때에는
원하는 데이터를 가져오기 위해서는 기본적으로 두번에 걸쳐 조인을 수행하게 되는데, 만약 [동아리 등록 테이블]을
조회하는 건수가 상당히 많아서 시스템에 많은 부담이 된다고 하면 어떻게 하겠는가?
(이런 분석은 데이터 사용량 분석과 업무 프로세스 분석을 이용해서 예상)
바로 이와 같은 상황에서 컬럼 역정규화를 하는 것이다.
컬럼 역정규화란 위와 같은 상황에서
조인을 통해 보고자 하는 컬럼을 [동아리 등록 테이블]에 물리적으로 만들어 놓고 데이터를 저장시킨 후에,
나중에 조회할 때는 조인을 하지 않고 그냥 조회만 하도록 하겠다는 것이다.
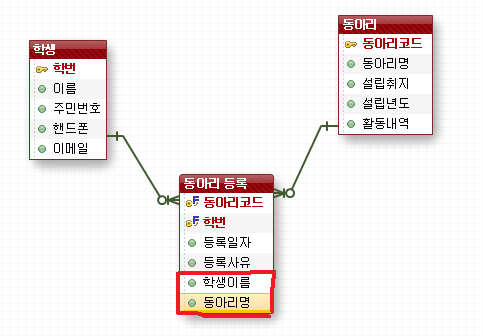
당연히 위와 같이 정의하게 되면, 2차 정규화에 위배되는 것이다.
그러나 성능 향상에 도움이 된다면, 윤리적으로 도덕적으로 문제가 되지 않는다.....
그런데 여기서 한가지 생각해볼 문제가 있다.
이렇게 컬럼 역정규화를 하게 되면,
당연히 [동아리 등록 테이블]의 레코드 길이가 길어지게 되므로 같은 양의 정보를 저장하는데,
훨씬 더 많은 페이지가 사용될 것이며, 그렇게 될 경우 기대만큼의 조회 성능이 나오지 않을수도 있다.
그렇다면 레코드의 길이를 적정한 상태로 유지하면서도 조회의 성능을 향상 시킬수 있는 방법은 없는 것일까?
적정한 선에서 서로 타협하면 훌륭한 모델을 만들어 낼수 있을것이다.
위의 역정규화된 학생이름 컬럼과 동아리명 컬럼 중에 학생이름은 일반적으로 6Byte 정도를 차지하지만,
동아리명 컬러에는 꽤나 긴 데이터들이 저장될 것이다.
그러므로 [동아리 등록 테이블]의 레코드 길이에 별로 부담스럽지 않은 학생이름 컬럼은 그대로 놔두고 동아리명 컬럼은
다시 제거해서 원상태로 되돌리면 어떨까?
이렇게 되면 [동아리 등록 테이블]의 레코드 길이도 적정한 선에서 유지할 수 있으며,
조회할 때도 처음과 같이 두번 조인을 해서 데이터를 가지고 오는것이 아니라 [동아리 테이블]과 한번만 조인을 하면
되므로 조회를 할때의 성능도 개선될수 있을 것이다.

이렇듯 역정규화란 상황에 따라서 개발자의 판단에 근거하여 그 결과가 달라질수 있기 때문에 역정규화를 수행한
이후에는 역정규화 작업에 대한 근거와 판단 내용 등을 자세히 기술해 놓는 작업이 필수적이라고 할 수 있다.
②파생컬럼의 생성
CREATE TABLE 판매
(
판매번호 INT IDENTITY PRIMARY KEY,
판매수량 INT,
판매단가 INT,
판매금액 AS(판매수량 * 판매단가)
);
파생 컬럼이란
위의 예에서 보듯이 판매금액 컬럼처럼 물리적으로 존재하는 컬럼이 아니라 테이블을 작성할 때의 계산 공식에 의해서
결과값을 표현해주기 위해서 작성하는 컬럼을 말한다.
이것 외에도 총점이나 평균 같은 컬럼도 파생 컬럼으로 정의될 수 있다.
이런 파생 컬럼은 물리적으로 데이터가 존재하는 것이 아니라 조회할 때마다 계산 공식을 적용하여 결과값을
보여주어야 하기에 조회할 때 부담요인으로 작용할수 있으며 파생컬럼 기준으로 데이터를 조회해아 하는 경우에도
당연히 성능상 문제가 발생할 수 밖에 없다.
그러므로 파생 컬럼을 생성한다는 것은
이러한 파생 컬럼을 물리적으로 만들어 놓고 실제 데이터를 저장함으로써, 데이터를 조회할 때 연산없이 바로 데이터를
조회할 수 있도록 하겠다는 것이다.
③테이블 분리

테이블은 행과 열로 이루어진 2차원 배열구조이므로 만일 테이블을 분리한다고 하면,
위 그림과 같이 레코드를 기준으로 분리하던지, 아니면 컬럼을 기준으로 분리 할수 있을 것이다.
레코드 분리, 컬럼 분리 등의 두가지 방법으로 컬럼을 분할하는 내용은 각각 중요한 의미를 갖고 있으므로 자세히
살펴봐야 한다.
-. 레코드 분리
회원수 100만명의 중형 규모의 사이트가 있다고 했을때
이 사이트를 주로 이용하는 회원은 보통 1/10 남짓 밖에는 되지 않을것이다.
이 10만명의 자주 이용하는 회원들과 나머지 90만명의 고객을 함께 관리 한다면 매번 로그인, 개인정보 등을 찾을때
마다 100만명중에 해당 하는 회원 한사람을 찾아야 하는 경우가 발생한다.
그래서 자주 찾는 주요 회원과 휴면회원으로 나눠서 관리하게 되면 자주 찾는 주요 회원들의 로그인 속도를 훨씬
개선할 수 있다.
-. 컬럼분리
컬럼을 기준으로 테이블을 분리할 때는
데이터 사용량을 기준으로 컬럼 분리를 할 수 있으며 , 사용자들의 프로세스 분석을 통해서 컬럼 분리를 할 수 있다.
앞에서 한 테이블의 컬럼의 숫자는 10개 내외가 될수 있도록 해야 한다고 했다.
컬럼을 기준으로 테이블을 분리할 때에는
업무적으로 자주 사용하는 컬럼과 자주 사용하지 않는 컬럼을 구분하여 자주 사용하는 컬럼은 그대로 두고 자주 사용
하지 않는 컬럼들을 따로 분리하자는 것이다.
㉮데이터 사용량을 기준으로 컬럼 분리

위 그림에서 보는 바와 같이 업무적으로 자주 사용하는 컬럼과 자주 사용하지 않는 컬럼을 분리해 보았다.
물론 이렇게 구분하기 위해서는 업무적으로 데이터 사용량 분석이 전제되어야 할것이며,
기존의 사원 테이블의 레코드의 길이에 비해서 자주 사용하는 부분을 분리해 낸 테이블은 훨씬 짧은 크기를 나타낸다.
업무적으로 자주 사용하는 데이터들은 기존에 비해서 절반 정도의 크기로 줄어들면서 조회시 성능이 상당히 개선될
것이다.
부가정보 관련 테이블은 1년에 한두번 조회하는 것들이라 조인으로 처리해도 된다.
㉯사용자들의 프로세스 분석을 통해 컬럼분리

우선 게시판에 처음 들어갔을때
게시판 목록을 구성하기 위해서 필요한 것들과 그 이후 사용자가 게시물을 선택 했을때 보여 주어야 하는것으로
구분할 수 있다.
전체를 다 저장하고 있는 테이블과 목록관련 상세 관련 2개의 테이블로 분리 한것을 비교해 봤을때 대략 2/3 정도로
줄어들었음을 확인할 수 있으며, 이것은 사용자들이 게시판에 들어갔을때 기존보다 2/3 정도 적은 페이지에 있는
데이터를 읽어서 게시판 목록을 구성할 수 있으므로 훨씬 더 빠르게 동작할 수 있을것이다.
④통계 테이블의 생성
판매 테이블의 경우 판매내역을 조회하기 위한 일반적인 조회의 유형도 많지만 여러가지 다양한 통계 정보를 얻기
위해서 조회하는 경우도 매우 많이 있다.
그런데 보통의 통계 데이터들은 Group By절을 많이 사용할것이고 이것이 시스템에 많은 부담을 주게 된다.
그렇기에 적절한 통계 테이블을 만들어서 커서나 트리거를 통해 미리 데이터를 입력해 놓으면,
나중에는 이 통계 테이블의 간단한 조회를 통해 원하는 결과를 쉽게 얻을수 있고 성능 향상에도 많은 도움을 줄수 있다.
Group By절에 의한 부담이 문제라면 이에 관한 역정규화의 정답은 통계 테이블을 작성하는것이 될수 있다.
⑤인공키(Surrogate Key) 생성
일반적으로 업무 현장을 가보면 여러개의 컬럼으로 기본키가 정의되어 있는 경우를 자주 보게 된다.
테이블을 디자인 할때 기본키 컬럼의 사이즈가 크거나 기본키 컬럼이 여러개로 구성된 경우에는 자식 테이블에 전이
되는 포린키(FK) 컬럼의 길이도 크게 되며, 조인의 조건을 정의할 때에도 여러번 조인의 조건을 정의해야 하므로 저장
공간이나 관련 프로세스를 처리하는데 있어서 당연히 비효율적일 수 밖에 없다.
특히나 기본키 컬럼에는 기본적으로 유니크한 인덱스가 자동으로 만들어지기 때문에 인덱스 또한 비효율적으로 구성
되므로, 저장공간의 문제와 성능상의 문제를 모두 해결할 수 있는 요긴한 방법으로 인공키가 사용될수 있다.
이러한 인공키는
일반적으로 IDENTITY 속성을 적용해서 일련번호 형식으로 정의함으로써 구현되며, 이미 데이터가 저장되어 있는
테이블인 경우에도 관련 어플리케이션의 수정을 최소화하면서 테이블의 물리적인 구조를 수정할 수 있는 방법이므로
단기간의 튜닝작업을 수행할 때 매우 효과적인 방법이 될수 있다.
간혹 이러한 일련번호 컬럼에 저장된 데이터가 업무적인 의미가 없어서 일련번호 사용을 꺼리는 경우가 있는데,
일련번호를 사용한다는 것은 관련 프로세스를 원활하게 처리하고 저장공간을 효율적으로 가져가기 위한 방안으로 사용
되는 것으로 결코 그 의미가 적다고 할수 없다.
⑥테이블 통합

위 그림처럼 데이터를 효율적으로 저장하기 위해서 테이블을 나누게 되면 데이터는 효율적으로 저장될 수 있지만,
데이터를 입력/수정/삭제할 때 서로를 참조해야만 하고, 데이터를 조회 할 때에는 조인을 해야만 한다.
그런데 궁극적으로 데이터 사용량이 많지 않거나 굳이 이렇게 테이블을 분리해서 얻는 이득이 별로 없었을때,
다시 원래대로 하나로 합치고 싶을수도 있을것이다.
테이블 통합이란
위와 같이 [고객 테이블]과 [자동차 테이블]을 하나로 합치는 것을 말하며, 이렇게 하나로 합치게 되면 원래의 테이블
모습으로 되돌아가게 된다.
그리고 슈퍼타입(Super Type)과 서브 타입(Sub Type)의 경우에도
데이터 양이 많지 않아서 테이블을 분리 했을때의 이점이 그다지 크지 않다고 판단되는 경우, 위와 같은 방법으로
테이블을 통합 할수 있는 것이다.
⑦코드 테이블 관리

위 그림처럼 등급, 지역, 장르 컬럼의 데이터가 반복되는 경우 데이터가 비효율적으로 저장되기 때문에 동일한 내용이
반복되는 경우 코드 테이블을 만들어서 코드를 반복 시키는 것이 훨씬 더 효율적일때 코드 테이블을 만들게 된다.
그리고 이러한 코드 테이블은 데이터베이스를 설계할 때 많이 만들어 질 수 있다.
물론 많이 만들어지는 것이 나쁜것은 아니지만 많이 만들어서 관리 하게 될 경우
각각의 코드 테이블과 관련된 동일한 유형의 코딩이 반복되며, 데이터를 읽어올 때도 코드 테이블의 데이터를 저장하고
있는 각각의 물리적인 페이지들을 모두 메모리에서 로딩해서 작업을 처리해야 하기 때문에 내부적으로도 비효율적으로
동작하게 된다.
이러한 코드 테이블은 그 유형이 비슷한 경우에는 하나로 묶어서 관리하는것이 일반적이다.
유사한 코드 테이블들을 하나로 합치게 되면
코드 관리 테이블은 메모리에 상주해 있을 가능성이 높아서 관련된 관련된 작업을 처리하거나 연산을 할 때,
매우 효율적으로 동작하게 된다.

'database > 모델링' 카테고리의 다른 글
| #5.관계형 데이터베이스 (0) | 2021.10.09 |
|---|---|
| #4.개념적 데이터 모델링 (0) | 2021.10.01 |
| #3.데이터베이스 모델링 (0) | 2021.10.01 |
| #2.시스템 구축 (0) | 2021.10.01 |
| #1.데이터베이스 시스템 (0) | 2021.10.01 |